实习工作中需要用到git,虽然之前接触过git,但是真正的实践过程中还是不够熟练,花了几天的时间,重新学了一次git。废话少说了,下面是git的相关笔记。
Git文件状态
要掌握git,首先要掌握git中的文件几个状态。git中的文件分为如下几个状态:
- history,又叫repository、快照,文件commit后所处的状态
- stage,又叫index,处于暂存区,文件add后所处状态
- unstage,又叫working,当前修改的文件,原始状态
通过不同的git命令,实现这3个状态的互相转换,下面这张图形象地表示出这个关系:
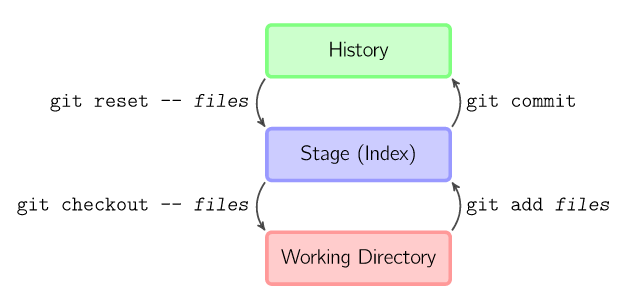
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
| git add files //把当前files文件放到暂存区,即working->stage git commit //提交暂存区的所有文件,生成快照,即stage->history ``` 理解好上面3个状态,接下来的学习也就容易许多。git在本地工作的流程大概如下这样: 1. 创建或编辑源代码文件 2. 当编辑好了之后,使用git add *files*命令把编辑完的文件放到暂存区,即文件从working->stage 3. 重复第1、2步骤,直到编辑完所有文件之后,执行git commit命令把暂存区中所有文件提交,生成快照。即stage->history. git commit本质就是向前移动HEAD指针,如下图: 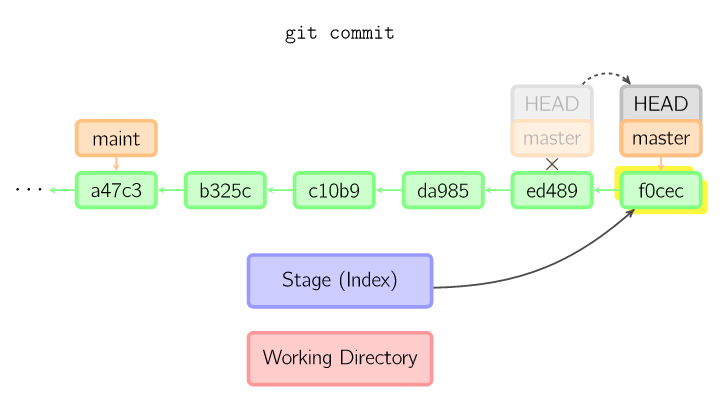 从上面的流程可以知道,文件经历working、stage、history等3个状态,如果中途,我想恢复文件到原先的状态,那该怎么办?不怕,git提供相当强的撤销功能。 git通过checkout和reset来实现文件的回滚,可以精确回滚到历史commit的版本或者暂存区的版本。 git checkout 和 git reset有什么不同?刚开始我也有同样的疑问,google了一下,发现reset主要对象HEAD指针,通过移动HEAD指针来切换版本,而不修改当前的working目录(通过--hard还是可以修改的),checkout的对象是working目录,把源文件回滚到某个版本。 下面是一些常用的命令: ```bash git reset HEAD //清空当前暂存区中所有文件,即把执行过git add files的file全部取消 git reset HEAD --files //把当前files文件恢复成最近一次快照的版本,history->working git checkout files //files文件恢复成暂存区中版本,stage->working
|
git reset
用于修改HEAD指针,–soft只修改HEAD指针,–hard也同时修改working目录。默认是–soft,不修改当前目录。
- git reset , 恢复到某个版本
- git reset HEAD file 清除暂存区中的file文件
- 当reset回以前的版本后,如何恢复为比当前版本更新的版本?其实reset只修改HEAD指针,没有删除历史记录,只要找出commit id就可以恢复了。可以通过git reflog查看之前HEAD的记录;也可以通过git log -all,查看所有的历史,找出commit id即可。
git checkout
命令有两种功能:checkout从history/stage中取出文件;切换分支branch
1 2
| git checkout HEAD --file //把file恢复成为HEAD的history版本,working->history git checkout files //把file恢复成暂存区版本,working->stage
|
diff比较
git支持多种功能比较,1个文件可以在history、stage、working状态互相比较
下面这张图足以说明一切:
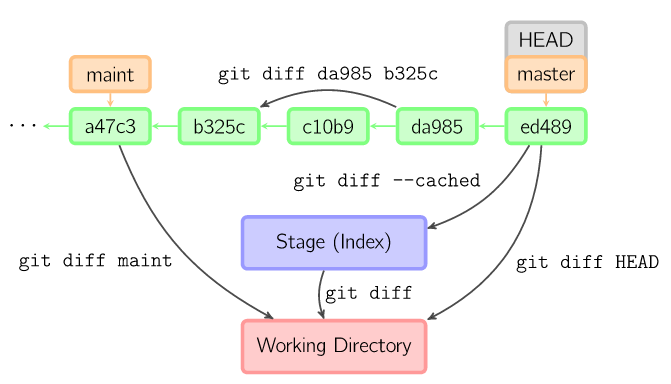
1 2 3
| git diff file //当前文件与暂存区的比较working diff stage git diff --cached //暂存区文件与history比较,stage diff working git diff HEAD file //当前文件与history比较, working diff history
|
Git remote
git除了本地仓库外,可以使用远程仓库,如github托管。git remote主要有如下几个操作:clone,fetch,pull,push
1 2 3 4 5
| git remote add [name] [url] //添加一个名叫name的远程仓库,地址为url git clone [url] //从remote仓库clone到本地,自动在本地创建一个叫origin的远程仓库 git fetch //从orgin仓库拉取数据到本地,更新origin/master指针,但是不会自动merge,需要手动merge到本地的master git pull // pull = fetch + merge git push //把本地仓库推送到origin的远程仓库
|
git fetch和git pull区别
fetch和pull都是更新远程repos到本地仓库,但是fetch更新完后,不会自动merge相应的分
,需要手动merge。而pull则自动merge。
fetch一般的用法如下:
1 2 3
| git fetch //同步远程repos, 更新本地仓库的所有origin/*分支信息 git diff master origin/master //比较本地的master和远程的master分支差异 git merge origin/master //合并远程的repos到本地的master分支上
|
也可以这样使用:
1 2 3 4
| git fetch origin master:tmp //从远程repos clone代码到本地的tmp分支上 git diff master tmp //比较本地的tmp和master分支的差异 git merge tmp //合并tmp分支到本地master git branch -d tmp //删除本地分支
|
而pull就直接fetch代码后再自动merge到本地分支上。
1
| git pull origin master //效果和上面的fetch效果一样,从origin远程仓库master分支merge到本地master分支
|
pull用起来更方便,不用手动merge,但是不够fetch安全,pull不需要人工查看就直接合并分支,有可能出现错误。
常用命令:
1 2 3 4 5
| // 把远程仓库master分支拉到本地新的new_branch分支(将本地创建新分支) git fetch origin master:new_branch // 不要使用下面的pull, 因为会以master作为基础,本地的master分支会被自动merge git pull origin master:new_branch
|
Git branch
git另外一个重要的特色就是branch,一个项目可以有多个branch。现在很多open source的开发都有几个branch:master、develop等,不同分支可以做不同的事情,如develop分支就是开发的分支;当软件有bug修复时,可以新创建一个bug修复分支,修复完毕后,再合并回来到master分支即可。
git默认的分支是master,下面是一些常用的命令:
1 2 3 4 5 6 7
| git branch [branch_name] //新建一个branch git branch -d [branch_name] //删除一个branch git checkout [branch_name] //切换branch git branch -a //列出全部的branch git push origin [branch_name] //上传branch到origin的远程仓库 git push origin [branch_name]:[remote_branch_name] //上传branch分支到origin的remote_branch_name分支上 git push origin :[branch_name] //删除远程仓库origin的branch
|
下面通过一个流程图看看branch是如何使用的:
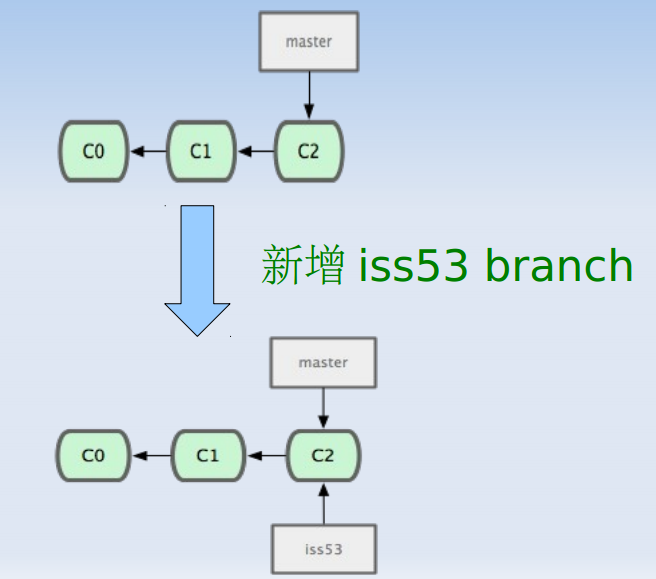
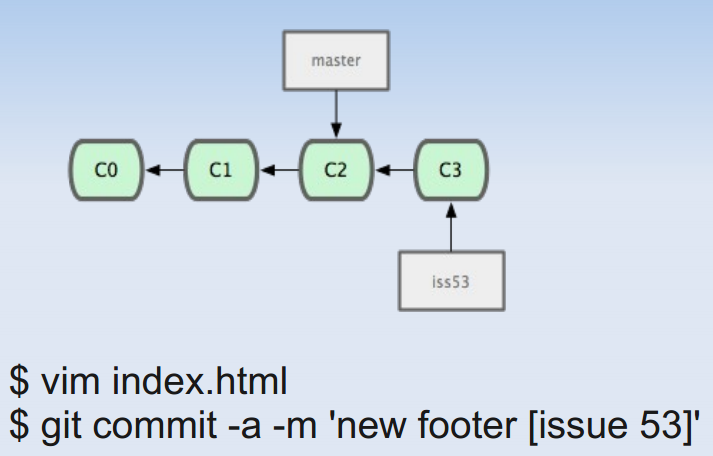
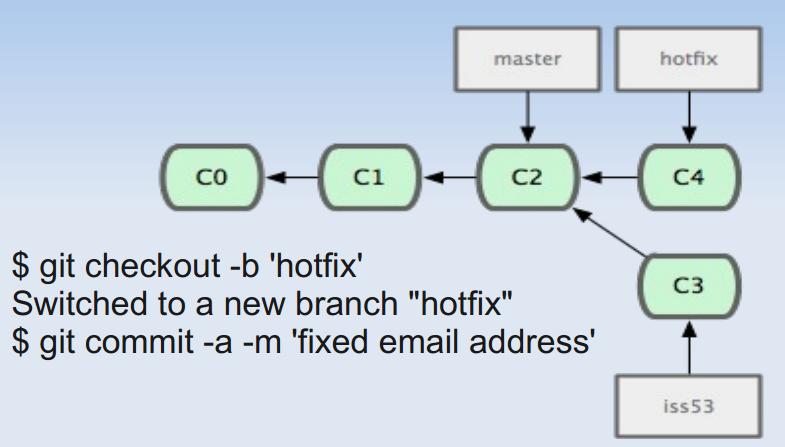
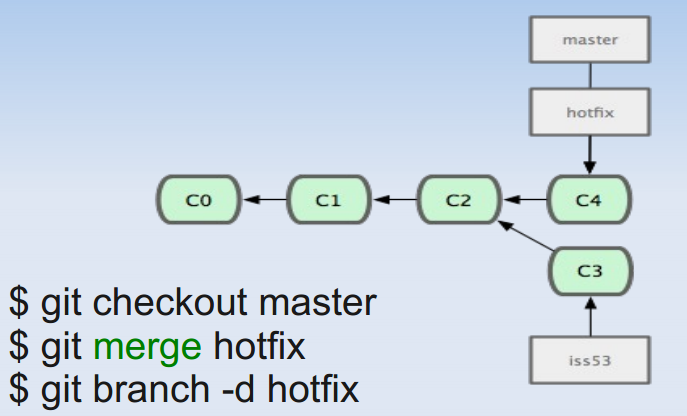
Git caret^ and tilde~
在使用Git中, 很常看见类似HEAD^, HEAD^^, HEAD~2这样的符号.会给初学者带来一定的疑惑.
下面解释一下这两个符号.
^, ~都是用于表示parent节点的.我们知道git每commit一次, 历史记录中就会产生一个节点.
随着commit次数的增多, 这些节点看起来就像一棵树.
可以用下面命令查看:
1 2 3
| $ git log --graph --oneline //terminal中显示 or $ gitk //图形画显示
|
这些树中每个节点都与之前的节点有所联系, 那就是祖先关系.
举个详细的例子:
1 2 3 4 5 6 7 8
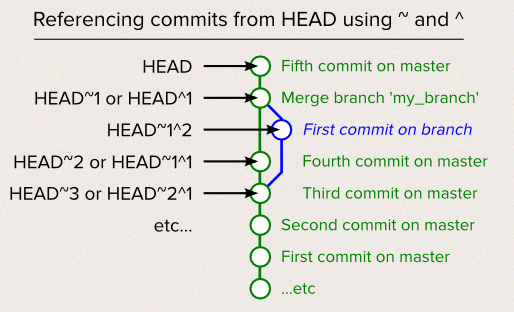
| HEAD^ :是HEAD^1的缩写, 表示当前HEAD指针指向的commit的第1个parent commit HEAD^2 :表示当前HEAD指针指向的commit的第2个parent commit. HEAD^^ :表示当前HEAD指针指向的commit的第1个parent的第1个parent commit. HEAD\^ ^2:表示当前HEAD指针指向的commit的第1个parent的第2个parent commit. HEAD~ :是HEAD~1的缩写,表示当前HEAD指针指向的commit的第1个parent commit. HEAD~2:表示当前HEAD指针指向的commit的第1个parent commit的第1个parent commit.
|
^后面数字表示当前层数的第几个parent节点.每出现1个^ 就表示更早一层祖先.
~就比^容易, 它只表示第1个parent. 后面跟的数字n表示与当前的结点相距n层的祖先.
^和~可以混合使用.~指明祖先所在层数, 然后使用^ 选择第几个parent节点.
即~选择深度, ^选择广度.
说了那么多文字, 下面的图相当简明地说明~和^的含义:
另外kernel git doc中也有一个很形象的图文说明:
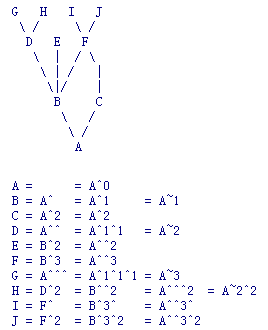
Git rebase
rebase代替merge
我们知道当需要把两个分支的代码合并时, 可以merge把两条分支合并在一次.
但是每次merge后, 都会在commit history中自动生成一个类似merge branch “branch_name”记录.
当merge的次数多了后, 会发现这种merge记录会充斥这整个history的记录.
而rebase可以合并两个分支而避免生成这个merge信息.
下面看下rebase的用法:
假设现在有下面两个分支:
1 2 3 4 5 6 7
| master | C1--C2--C3--C4 \ C5--C6 | mywork
|
当在master分支使用下面命令合并mywork分支后:
$ git merge mywork
就会成如下:
1 2 3 4 5
| C1--C2--C3--C4- master \ \ | C5--C6---C8 | mywork
|
但在master分支使用rebase命令:
历史记录就会变成如下:
1 2 3
| master | C1--C5--C6--C2'--C3'--C4'
|
两条链合并成1条链了.
上述rebase命令做了如下操作:
- 把当前master分支C2, C3, C4的commit取消掉并暂存起来.
- 然后把mywork的分支的commit更新到master分支上.
- 最后把暂存的C2, C3, C4 commits重新搬到master分支上.
如果rebase过程中产生冲突, 需要手动解决后, 再使用命令继续:
1 2
| $git rebase --continue $git rebase --abort //取消当前rebase操作
|
-i交互模式
当我们提交的commit写得很烂, 是否有办法修改已经提交的commit?
答案是有的.就是通过rebase的交互模式.
当然可以通过git commit –amend修改最近一次的commit.
但是rebase更加强大, 可以任意操作过去的任何一次commit.可以添加,删除,修改commit message等等.
假设我有下面的提交记录:
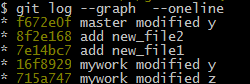
我想把add new_file2和add new_file1两个commit合并在一起.
通过执行命令:
1
| $ git rebase -i 16f8929 //16f8929是add new_file1记录的父记录
|
就会弹出如下的内容让你编辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| pick bfb12ab add new\_file1 pick 89f5f14 add new\_file2 pick 1a5bc91 master modified y # Rebase 16f8929..1a5bc91 onto 16f8929 # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # # If you remove a line here THAT COMMIT WILL BE LOST. # However, if you remove everything, the rebase will be aborted. #
|
看到前3行(pick开头), 表示的是commit id为16f8929的所有子孙commits.
commit时间越先, 就排在前面.即越新的commit就排在最后.
找到我们想要的修改的2个commits, 分别是第1个和第2个.
注意到#后面的提示, 有各种操作, 我们要合并, 就是操作squash.
把第2行的pick修改成squash.然后退出.
退出后, git会执行rebase操作. 进入编辑message的界面, 有如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| # This is a combination of 2 commits. # The first commit's message is: add new_file1 # This is the 2nd commit message: add new_file2 # Please enter the commit message for your changes. Lines starting # with '#' will be ignored, and an empty message aborts the commit. # Not currently on any branch. # Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # # new file: new_file1 # new file: new_file2
|
这个commit message就是合并add new_file1和add new_file2的commit message.
输入相应的message, 然后退出.
Git就会把原先的add new_file两个commit合并成新的commit了.
这仅仅是一个例子.如果想要更多的操作, 可以看到rebase命令后弹出的编辑菜单中的选项, 里面的注释已经很齐全了.
其中最常见的:
- rework 就是修改commit的message
- edit 修改commit, 可以添加/删除文件后, 然后使用git rebase –continue执行rebase
- squash 用于合并commit, 把commit合并到前一个.
Patch功能
1 2 3 4 5 6 7 8 9 10
| // 创建最新commit patch git format-patch -1 HEAD // 创建指定commit的patach git format-patch -1 <commit-id> // 创建所有patch git format-patch --root // 假设当前分支为branch1 // 创建所有branch1相对master分支的patch git format-patch master
|
Git am
1 2
| // 打patch git am XX.patch
|
打patch过程中错误处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| git am XX.patch ... When you have resolved this problem run "git am --resolved". If you would prefer to skip this patch, instead run "git am --skip". To restore the original branch and stop patching run "git am --abort". // 手动打patch // 没有冲突的文件会自动处理后,有冲突的会产生一个相应的*.rej文件 git apply --reject XX.patch //根据生成的rej文件处理冲突文件后 git add XX //git am --resolved
|
总结
最后,附上一张自己总结的Git思维导向图
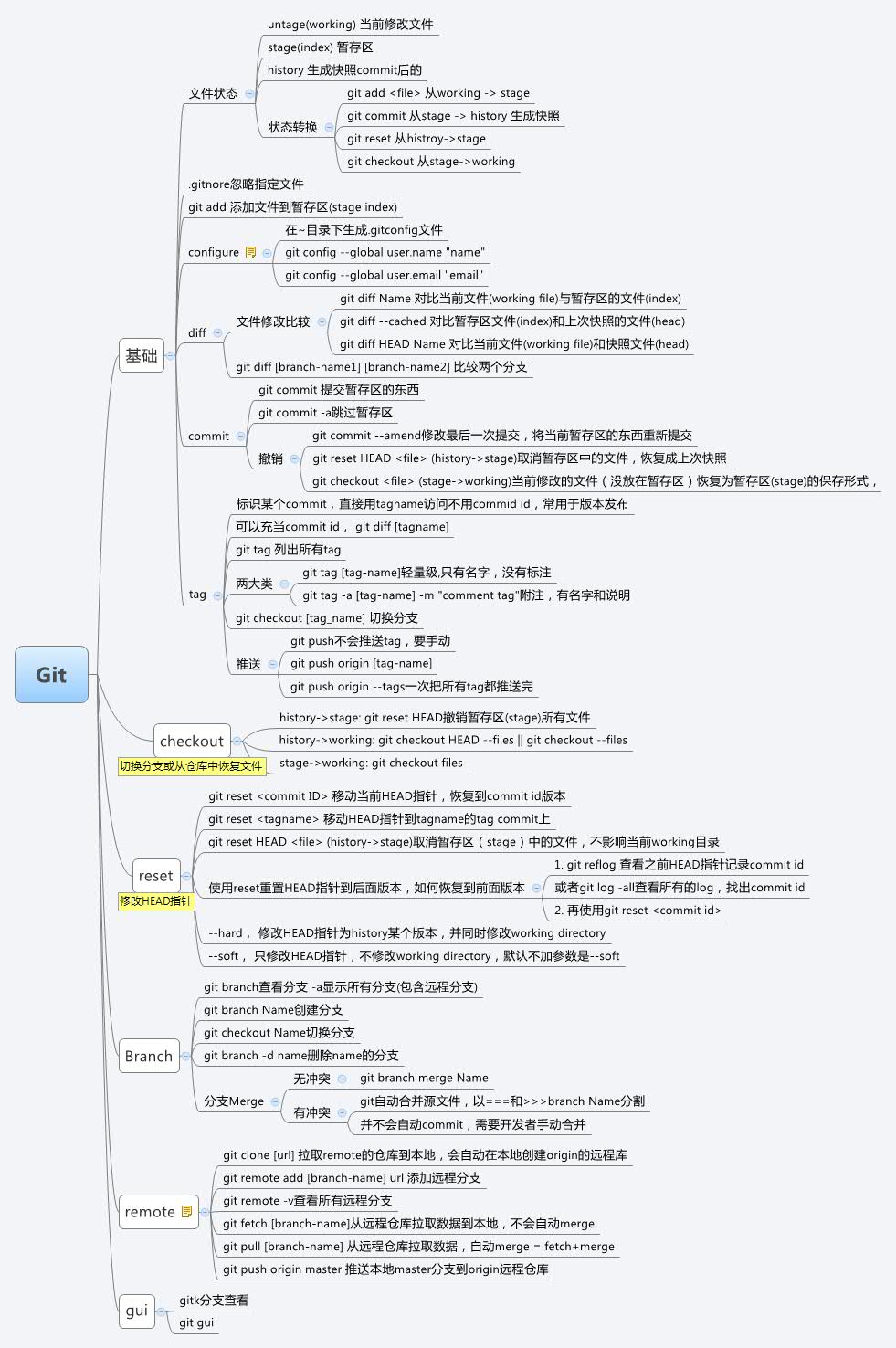
Reference
- A Visual Git Reference
- Pro git
- 新人 Git 版本控制教學
- git the basics
- Git中的fetch和pull
- git-rev-parse(1) Manual Page
- Git caret and tilde
- Git Community Book